突破實時生成瓶頸,Soul CEO張璐團隊發布開源模型SoulX-LiveAct
突破實時生成瓶頸,Soul CEO張璐團隊發布開源模型SoulX-LiveAct
聚焦長時穩定與實時推理,Soul CEO張璐團隊開源SoulX-LiveAct模型
近日,Soul App CEO張璐團隊宣布,其AI研究團隊Soul AI Lab正式發布開源模型SoulX-LiveAct。作為面向實時數字人生成的重要技術成果,該模型圍繞“長時穩定”與“實時流式”兩大核心目標,對現有生成范式進行了系統性優化。在數字人直播、視頻播客以及實時互動場景不斷擴展的背景下,SoulX-LiveAct為實時生成技術的工程化落地提供了新的實現路徑。
隨著人工智能在內容生成領域的應用加速,數字人技術逐漸從實驗性演示走向實際應用場景。然而,在長時間運行的情況下,傳統生成模型往往難以保持一致表現。當視頻生成時長延伸至分鐘甚至小時級,模型容易出現身份漂移、細節退化、畫面閃爍等問題,同時推理成本也會隨時間增加而上升。
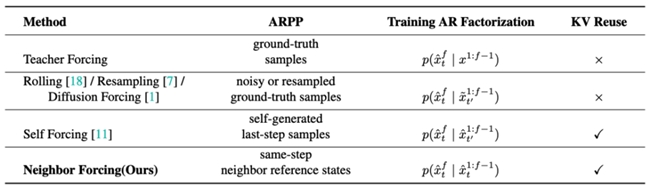
針對上述挑戰,SoulX-LiveAct在整體架構上采用自回歸擴散(AR Diffusion)范式,并引入Neighbor Forcing與ConvKV Memory兩項關鍵機制,構建面向長時序生成的穩定體系。在具體實現上,模型以chunk為基本生成單元,通過逐段生成與上下文銜接,實現連續的視頻輸出。在每個chunk內部,擴散模型負責細節建模,而在chunk之間,通過條件信息傳遞實現動作與身份的一致延續,從而形成完整的流式推理閉環。
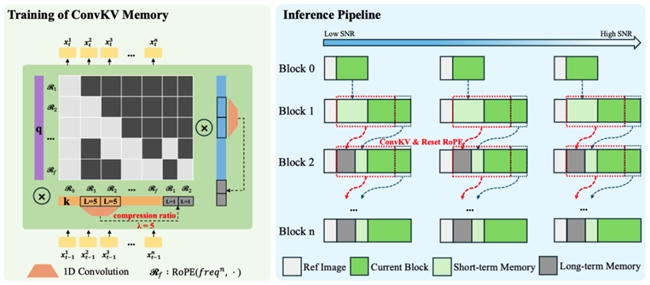
在核心機制方面,Neighbor Forcing通過在同一擴散步內傳播相鄰幀的latent信息,使模型在統一的噪聲語義空間中進行預測,有效降低訓練與推理過程中因分布不一致帶來的不穩定因素。與此同時,ConvKV Memory對歷史信息進行結構性壓縮,將傳統線性增長的緩存轉化為“短期精確+長期壓縮”的組合形式:近期信息保留高精度以保證局部細節,遠期信息通過輕量卷積進行壓縮,從而在控制內存占用的同時保留關鍵上下文信息。此外,模型還通過RoPE Reset對位置編碼進行對齊,進一步減少長序列生成中的位置漂移問題。
在推理效率方面,SoulX-LiveAct強調“穩定延遲”與“恒定顯存”。通過ConvKV Memory機制,歷史信息不再隨時間線性增長,使顯存占用保持在固定范圍內。這一設計使得模型在長時間運行過程中,計算與通信成本保持穩定,不會隨著視頻長度增加而顯著上升。在實際性能表現上,系統在512×512分辨率下,可在2×H100/H200硬件條件下實現20 FPS的流式推理,同時端到端延遲約為0.94秒,計算成本為27.2 TFLOPs/frame,體現出較為均衡的實時性與資源利用效率。
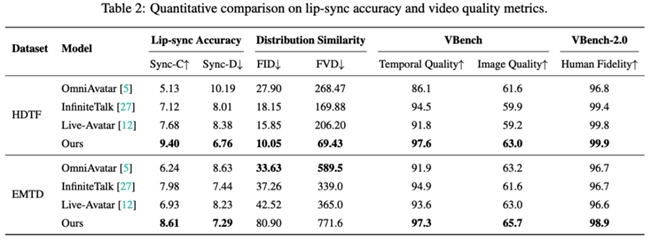
在多項評測基準中,SoulX-LiveAct也展示了其綜合性能優勢。在HDTF數據集上,模型取得9.40的Sync-C與6.76的Sync-D,在分布相似性指標上達到10.05 FID與69.43 FVD,并在VBench中獲得97.6的Temporal Quality與63.0的Image Quality,VBench-2.0的Human Fidelity達到99.9。在EMTD數據集上,模型同樣保持領先表現,取得8.61 Sync-C與7.29 Sync-D,并在VBench中實現97.3的Temporal Quality與65.7的Image Quality,Human Fidelity達到98.9。這些結果表明,該模型在口型同步、動作一致性以及整體畫面穩定性方面具備較強能力。
基于上述性能表現,SoulX-LiveAct能夠支持多種需要長期在線運行的應用場景,包括數字人直播、AI教育、智慧服務終端以及知識內容生產等。在開放世界互動場景中,數字角色需要在長時間交互過程中持續保持一致表達能力。SoulX-LiveAct在全身動作數據集上的表現以及其實時流式推理能力,使其具備支持此類復雜場景的基礎條件。
SoulX-LiveAct的發布,也延續了Soul AI團隊在實時數字人方向的技術布局。此前,團隊已開源SoulX-FlashTalk與SoulX-FlashHead兩個模型,分別在超低延遲與輕量化部署方面進行了探索。此外,團隊還在語音與交互領域推出了SoulX-Podcast、SoulX-Singer以及SoulX-Duplug等模型與模塊,逐步構建圍繞“實時交互”的多模態技術體系。
通過持續開放模型與技術方案,Soul CEO張璐團隊不僅推動了自身AI能力的迭代,也為開發者社區提供了可復用的技術基礎,促進更多應用場景的探索與落地。
免責聲明:市場有風險,選擇需謹慎!此文僅供參考,不作買賣依據。
標簽:
推薦













































財富更多》
-

回購增持“重質提效” 龍頭公司“大手筆”傳遞價值信號
記者高志剛郭成林進入4月,京東方A、盛...
-
馬士基:是否通過霍爾木茲海峽將基于持續的風險評估、對安全局勢的密切監控|觀熱點
馬士基表示,關于是否通過霍爾木茲海峽...
-
3073只股短線走穩 站上五日均線
證券時報•數據寶統計,截至今日上...
-
化肥概念持續走高 魯西化工等漲停
化肥概念持續走高魯西化工等漲停
-
陳光標發抖音稱張雪遲遲未提車 他已向嫣然醫院匯款捐贈1000萬元
【陳光標發抖音稱張雪遲遲未提車他已向...
動態更多》
熱點
- 4月7日科創人工智能ETF國泰基金份額減少300萬份,重倉股金山辦公、瀾起科技、寒武紀|焦點熱門
- 今日快看!2026年清明假期 全社會跨區域人員流動量超8.4億人次
- 快訊:女足國腳邵子欽加盟本菲卡 下賽季有望參加女足歐冠
- 零售商股票市值排行榜(3月25日)
- PriceSeek重點提醒:中國藍星苯酚價格上調200元
- 恒生電子今日大宗交易溢價成交253.57萬股,成交額6430.55萬元
- 滾動:我省多地中小學迎來加長春假 與清明節假期無縫銜接 有的最長可連休6天
- 微資訊!4月1日科創人工智能ETF易方達基金份額減少1400萬份,重倉股金山辦公、寒武紀、瀾起科技
- 天岳先進午后漲超5% 2025年實現總收入約14.65億元
- 光伏組件龍頭股_光伏組件龍頭股票一覽表(3/25)|實時
- 恒生電子今日大宗交易溢價成交253.57萬股,成交額6430.55萬元
- [快訊]下周二8股面臨拋壓 4.0億股解禁 新資訊
- 生意社:4月3日烏海市場煉焦煤價格下跌_每日短訊
- 焦點關注:浙江嵊州: 茶園光伏發電站"照亮"茶農致富路
- 敏昂萊當選緬甸新任總統_今日熱門
- 清明假期哪些路段易擁堵 最新交通出行情況一覽
- 今日要聞!萬人圍觀無人出手,西王食品2億股股份為何流拍?
- 每日看點!南陽鵬承工藝品有限公司成立 注冊資本10萬人民幣
- 中歐班列中通道一季度通行量創新高 每日看點
- 足壇一夜動態:U16國足0-1巴西!巴薩女足12-2皇馬 曼城失核心 熱門看點
- 美股三大股指跌幅進一步收窄,截至發稿,道瓊斯指數跌0.43%,標普500指數跌0.23%,納斯達克綜合指數跌0.50%
- 圖解財報:節能環境全年歸母凈利潤8.71億元,同比增長43.89% 動態焦點
- 華建集團:2025年歸母凈利潤7162.73萬元,同比下降81.71% 焦點播報
- 高亮雙色溫 專業新標桿!金貝EF-200X雙色溫攝影補光燈上市
- 最資訊丨福田汽車:2026年公司將圍繞氫能全產業鏈深化布局
- [快訊]賽騰股份發布解除質押公告一股東累計質押2325.00萬股
- TD Cowen上調多只油氣股目標價
- 滾動:我省多地中小學迎來加長春假 與清明節假期無縫銜接 有的最長可連休6天
- 年輕人為啥流行找“搭子”?
- 微資訊!4月1日科創人工智能ETF易方達基金份額減少1400萬份,重倉股金山辦公、寒武紀、瀾起科技
- 曲江文旅(600706):西安曲江文化旅游股份有限公司關于控股股東部分股權拍賣撤回、解除凍結及質押公告 實時焦點
- 天岳先進午后漲超5% 2025年實現總收入約14.65億元
- 鈴木彩艷:下半場英格蘭隊角球很多,我們全隊團結一心防守
- 每日信息:老人陷泥潭七八個小時 家人發現其未回家報警 警方搭梯刨泥緊急救出七旬婆婆
- 熱門:生意社:4月1日湖北當陽華強三聚氰胺價格上漲
- 中國科大團隊揭開疼痛的晝夜波動密碼
- 牛眼觀?教育說|讓“健康第一”在第一個春假里生根開花
- 行業洞察 | TMIC×Flywheel飛未聯合發布《2026天貓音箱音響行業白皮書》
- 光伏組件龍頭股_光伏組件龍頭股票一覽表(3/25)|實時
- 3月市場先揚后抑,4月低位箱體震蕩居多-當前關注
- 速遞!力箭二號首飛成功,二季度有望開啟可回收火箭首飛潮,航空航天ETF華夏(159227)漲0.23%
- 上海實業環境子公司擬2.7億元收購清暢水務及清朗水務100%股權
- 焦點資訊:凱萊英早盤漲逾15% 全年歸母凈利潤約11.33億元同比增加19.35%
- 均勝電子:與均普智能簽訂采購框架協議|每日快報
- 觀熱點:華智數媒:2025年虧損4.02億元
- 每日簡訊:中航沈飛:2025年凈利潤同比增長3.65% 擬10派2.65元
- 晶晨股份:2025年凈利潤8.73億元 同比增長6.21%
- 印尼說一艘船沉沒27人失蹤-今日關注
- 九號公司確認部分兩輪車優惠縮水|微動態
- 每日播報!開展“三服務”專項行動,精準搭建就業“供需橋”
- 國科天成創歷史新高,融資客減倉
- 焦點訊息:蘇州科維恩機電科技有限公司成立 注冊資本10萬人民幣
- 市場沒有恐慌,反而嘗試修復
- 里程碑刷新:蔚來firefly螢火蟲歷時11個月,達成5萬臺交付|最新
- 米體:萊奧恥骨傷復雜難解,手術也未必能根治
- 可精準殺傷癌細胞!我國“治療利器”實現量產
- 0-4慘敗!韓國球迷哀嘆:我們已不配跟日本比 只能找中國隊尋安慰
- 筠連縣術德木材加工廠(個體工商戶)成立 注冊資本50萬人民幣|今日熱訊
- 友誼賽登場,賈伊和加布里埃爾-羅哈斯迎來阿根廷國家隊首秀
- 南部戰區新聞發言人翟士臣就菲海軍艦艇對我危險接近發表談話_視焦點訊
- 新紐科技2025年收入達308.7百萬元,經營底盤穩步夯實
- 建設銀行:三方面重點布局人工智能領域 構建“人+數字員工”協同模式
- 色譜乙腈商品報價動態(2026-03-27)-熱文
- 圖解財報:漫步者全年歸母凈利潤4.31億元,同比減少4.06% 看點
- 京東發布全國首個互聯網寵物犬貓交易標準|當前聚焦
- 每日訊息!太保產險總經理陳輝:2025年公司新能源車險增速高于整體車險增速,未來新能源車替代率會持續提升
- 里昂:維持海天味業(03288)“跑贏大市”評級 目標價上調至40港元-當前聚焦
- 焦點要聞:PriceSeek重點提醒:巴里克放緩Reko Diq銅金礦開發
- 【時快訊】煙花爆竹強制性國家標準5月1日起實施 該領域湖南牽頭制定的標準占比超七成
- 時訊:禁或用?別忽視“小蜜蜂”背后的教育真問題
- 小魚盈通(00139.HK)2025年度除所得稅后虧損凈額1.91億港元|當前聚焦
- 快播:斯特羅姆將為馬來西亞海上項目供應絕緣熱塑性復合材料管跨接器
- 今日熱搜:創業板指數沖高回落跌逾1%,創業板ETF易方達(159915)全天凈申購超1.2億份
- 金貝 HD-46閃光燈上市——可能是你的第一盞圓頭機頂閃光燈
- 大灣區超級工程獅子洋大橋主塔封頂 每日熱文
- 港股耐世特再跌超4%
- 3月26日固廢治理板塊跌幅達2% 熱推薦
- 安全漏洞引行業警惕 養蝦優選本地化部署
- 焦點熱議:3月25日鵬華中證內地低碳經濟主題ETF基金份額減少100萬份,重倉股寧德時代、長江電力、陽光電源
- 和訊投顧李景峰:谷歌發布新技術!A股誰最受益?|每日熱聞
- 北京:公園市集+地標文創 點亮春日消費
- 今日視點:寶尊(09991)2025年Q4凈收入32億 同比增長6% 三年戰略轉型圓滿收官
- 每日訊息!生意社:3月25日華北地區醋酸行情整理運行
- 2026主流直播補光燈推薦|金貝JL系列憑什么成為主播首選?
- 即時:智立方:公司持續推進與行業客戶的業務合作、技術交流及產品驗證工作
- 近4萬人94%活躍率!中建五局攜手絢星跑穩數智化學習之路
- 里昂:農夫山泉(09633)去年下半年業績勝預期 維持跑贏大市評級 目標價57.6港元 新資訊
- 市場放量反彈,滬指半日漲0.88%,關注A500ETF易方達(159361)、滬深300ETF易方達(510310)表現 看熱訊
- 讓AI在學術規范下賦能科研工作_每日觀察
- 煙臺毓璜頂醫院專家直播3月25日開講:肺結節的科學認識與從容應對
- 一加 15T 售價 4299 元起,性能續航超越大屏,旗艦體驗完勝小屏
- 每日動態!博濟醫藥:公司累計減持回購股份約267萬股
- 小米集團(01810)CFO林世偉:小米2025年回購股票金額達63億元 2026年繼續加碼回購力度
- 2026年3月24日絲麗雅粘膠短纖價格動態
- iPhone史上最大規模產品革新來了: 20周年紀念版+折疊屏雙旗艦
- 穩油價,該出手時就出手!
- 微視頻丨跨越千年的治水智慧
- 應縣木塔即將全部拆卸落地大修?官方回應-當前熱門
- 收好這份地產的股票名單(3/16)
- 中國1-2月多晶硅進口量驟降,前兩個月國內產量下降明顯 滾動
- 一加 15T 搭載小屏唯一 165Hz 旗艦小直屏,引領小屏屏顯體驗大換代
- 2026機頂閃光燈大對比:金貝 vs 神牛 vs 紐爾!金貝HD2PLUS更勝一籌
- 一加 15T 搭載 LUMO 凝光影像系統,5000 萬像素潛望長焦輕松定格絕美瞬間
- 旗艦性能滿血釋放,一加 15T 成小屏旗艦性能續航雙冠王
- 2026影棚閃光燈怎么選?金貝 VS 神牛 高性價比影室閃光燈推薦!
- 榮泰RT9000新品系列亮相AWE 2026 開啟全身拉伸新時代
- 又小又強又美又全面,「小屏大魔王」一加 15T 官宣 3 月 24 日正式發布
- CP+ 2026佳能研發團隊專訪 光學突破、概念探索與 PowerShot 三十載煥新
- 榮泰以硬核技術革新定義智能按摩新高度,解鎖全場景健康理療新體驗
- 巴基斯坦金礦年產值超十億,天空工場創投基金被投企業「深脈礦業」攜智能勘探解決方案亮相AWE 2026
- 同功率比配置!神牛南光對比下金貝 JL160/220/300BI 性價比更優
- 微短劇,游園會……招行信用卡把消保宣教“玩出花”
- 金貝 TR-A1迷你引閃器上市!通吃全品牌,盤活你的閃光燈
- 鼻竇炎手術后還會復發嗎?專家提醒:關鍵在于長期管理
- 專業機頂閃光燈優選金貝HD2PLUS!適配戶外春日人像拍攝
- 艷存膠原水光:別只給臉“灌水”,先補“鋼筋”才是正解
- 北京樓盤測評|昌平馬池口 國譽燕園朗潤 微資訊
- 今日訊!創科實業(00669.HK)發布股份變動公告
- 速訊:禹洲集團(01628)2月合約銷售金額3.62億元
- 內容正在升級改造,請稍后再試!_微速訊
- AWE2026倒計時!海信攜三大彩色光源技術亮劍,UX2026款迎來國內首秀
- 武漢晴川閣重新開放,登樓賞“晴川吹雪”
- 每日觀點:杭州一宅地15.86億元成交 溢價率16.11%
- 3月9日基金調研瞄準這些公司
- 前兩個月我國貨物貿易出口4.62萬億元,同比增長19.2%
- 頭條焦點:米蘭冬殘奧會:旗手劉思彤再獲一銅
- 生意社:3月9日亞洲地區對二甲苯收盤價格上漲
- 今亮點!AI輔助麻醉監測:智能時代如何讓手術更安全
- 同花順去年凈利同比增75%至32億元,擬10轉4派51元 當前看點
- 一加攜手電競生態伙伴齊聚中傳,「一加杯」高校槍神大賽正式開幕
- 一地兩用,大化光伏板下春耕忙_每日消息
- 快播:[快訊]羅 牛 山:2026年2月畜牧行業銷售簡報
- 菲林普利S型破譯淺層密碼:讓“皮相”自動再生的隱藏開關
- 群洞察談AI落地:我們沒有做一個接龍工具,而是在讓AI學會讀群聊
- 場均13+2+3,傳射兼備!火箭隊后衛或成最佳第6人?美媒列4人名單